NLP词嵌入Word embedding实战项目 (tensorflow2.0官方教程翻译)
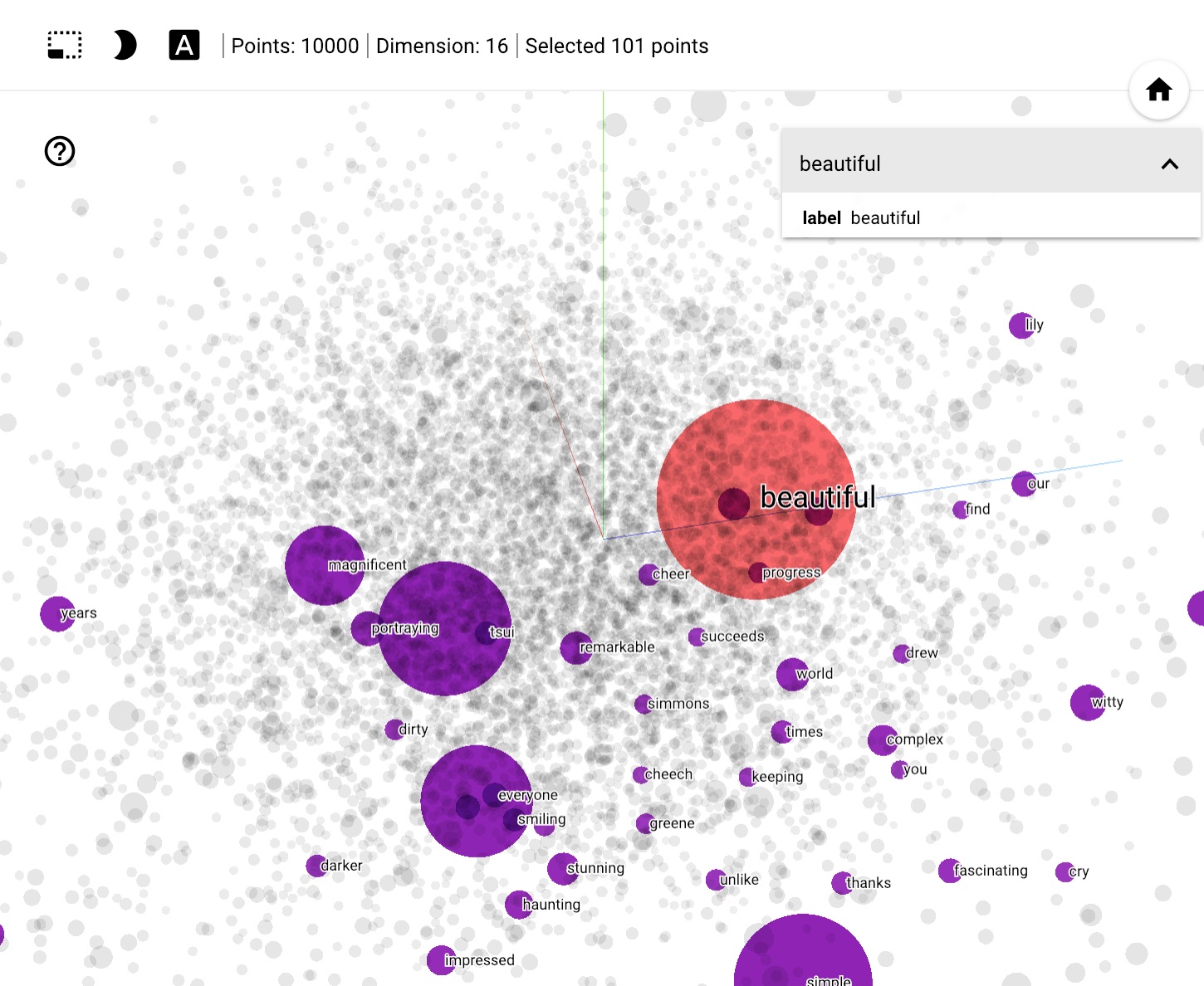
本文介绍词嵌入向量 Word embedding,包含完整的代码,可以在小型数据集上从零开始训练词嵌入,并使用Embedding Projector 可视化这些嵌入,如下图所示:
词嵌入向量(Word Embedding)是NLP里面一个重要的概念,我们可以利用 WordEmbedding 将一个单词转换成固定长度的向量表示,从而便于进行数学处理。
1. 将文本表示为数字
机器学习模型以向量(数字数组)作为输入,在处理文本时,我们必须首先想出一个策略,将字符串转换为数字(或将文本“向量化”),然后再将其提供给模型。在本节中,我们将研究三种策略。
1.1. 独热编码(One-hot encodings)
首先,我们可以用“one-hot”对词汇的每个单词进行编码,想想“the cat sat on the mat”这句话,这个句子中的词汇(或独特的单词)是(cat,mat,on,The),为了表示每个单词,我们将创建一个长度等于词汇表的零向量,然后再对应单词的索引中放置一个1。这种方法如下图所示:
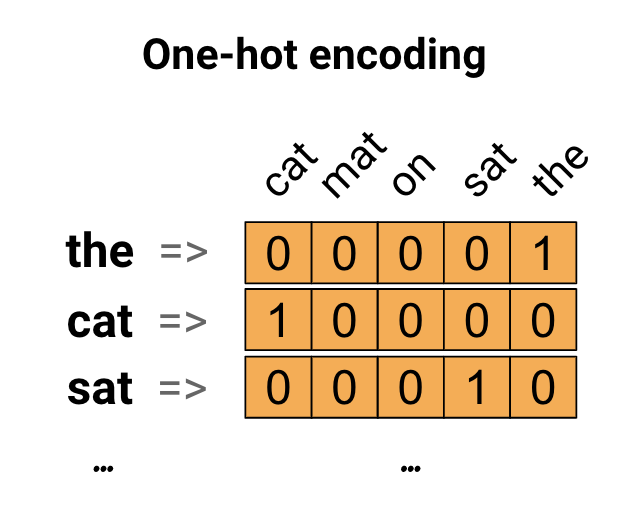
为了创建包含句子编码的向量,我们可以连接每个单词的one-hot向量。
关键点:这种方法是低效的,一个热编码的向量是稀疏的(意思是,大多数指标是零)。假设我们有10000个单词,要对每个单词进行一个热编码,我们将创建一个向量,其中99.99%的元素为零。
1.2. 用唯一的数字编码每个单词
我们尝试第二种方法,使用唯一的数字编码每个单词。继续上面的例子,我们可以将1赋值给“cat”,将2赋值给“mat”,以此类推,然后我们可以将句子“The cat sat on the mat”编码为像[5, 1, 4, 3, 5, 2]这样的密集向量。这种方法很有效,我们现有有一个稠密的向量(所有元素都是满的),而不是稀疏的向量。
然而,这种方法有两个缺点:
- 整数编码是任意的(它不捕获单词之间的任何关系)。
- 对于模型来说,整数编码的解释是很有挑战性的。例如,线性分类器为每个特征学习单个权重。由于任何两个单词的相似性与它们编码的相似性之间没有关系,所以这种特征权重组合没有意义。
1.3. 词嵌入
词嵌入为我们提供了一种使用高效、密集表示的方法,其中相似的单词具有相似的编码,重要的是,我们不必手工指定这种编码,嵌入是浮点值的密集向量(向量的长度是您指定的参数),它们不是手工指定嵌入的值,而是可训练的参数(模型在训练期间学习的权重,与模型学习密集层的权重的方法相同)。通常会看到8维(对于小数据集)的词嵌入,在处理大型数据集时最多可达1024维。更高维度的嵌入可以捕获单词之间的细粒度关系,但需要更多的数据来学习。
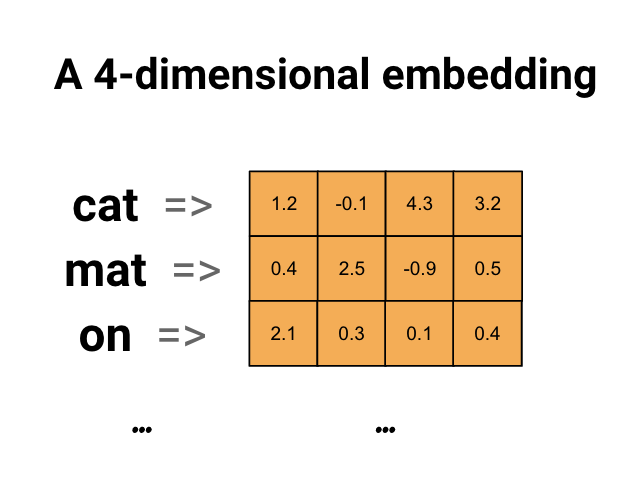
上面是词嵌入的图表,每个单词表示为浮点值的4维向量,另一种考虑嵌入的方法是“查找表”,在学习了这些权重之后,我们可以通过查找表中对应的密集向量来编码每个单词。
2. 利用 Embedding 层学习词嵌入
Keras可以轻松使用词嵌入。我们来看看 Embedding 层。
x1from __future__ import absolute_import, division, print_function, unicode_literals23# !pip install tf-nightly-2.0-preview4import tensorflow as tf56from tensorflow import keras7from tensorflow.keras import layers89# Embedding层至少需要两个参数: 10# 词汇表中可能的单词数量,这里是1000(1+最大单词索引); 11# embeddings的维数,这里是32.。12embedding_layer = layers.Embedding(1000, 32)Embedding层可以理解为一个查询表,它从整数索引(表示特定的单词)映射到密集向量(它们的嵌入)。嵌入的维数(或宽度)是一个参数,您可以用它进行试验,看看什么对您的问题有效,这与您在一个密集层中对神经元数量进行试验的方法非常相似。
创建Embedding层时,嵌入的权重会随机初始化(就像任何其他层一样),在训练期间,它们通过反向传播逐渐调整,一旦经过训练,学习的词嵌入将粗略地编码单词之间的相似性(因为它们是针对您的模型所训练的特定问题而学习的)。
作为输入,Embedding层采用形状(samples, sequence_length)的整数2D张量,其中每个条目都是整数序列,它可以嵌入可以变长度的序列。您可以使用形状(32, 10) (批次为32个长度为10的序列)或(64, 15) (批次为64个长度为15的序列)导入上述批次的嵌入层,批处理中的序列必须具有相同的长度,因此较短的序列应该用零填充,较长的序列应该被截断。
作为输出,Embedding层返回一个形状(samples, sequence_length, embedding_dimensionality)的三维浮点张量,这样一个三维张量可以由一个RNN层来处理,也可以简单地由一个扁平化或合并的密集层处理。我们将在本教程中展示第一种方法,您可以参考使用RNN的文本分类来学习第一种方法。
3. 从头开始学习嵌入
我们将在 IMDB 影评上训练一个情感分类器,在这个过程中,我们将从头开始学习嵌入,通过下载和预处理数据集的代码快速开始(请参阅本教程tutorial了解更多细节)。
xxxxxxxxxx51vocab_size = 100002imdb = keras.datasets.imdb3(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=vocab_size)45print(train_data[0])xxxxxxxxxx11[1, 14, 22, 16, 43, 530, 973, 1622, 1385, 65, 458, 4468, 66, 3941, 4, 173, 36, 256, 5, 25, 100, 43, 838, 112, 50, 670, 2, 9, 35, 480, ...]
导入时,评论文本是整数编码的(每个整数代表字典中的特定单词)。
3.1. 将整数转换会单词
了解如何将整数转换回文本可能很有用,在这里我们将创建一个辅助函数来查询包含整数到字符串映射的字典对象:
xxxxxxxxxx161# 将单词映射到整数索引的字典2word_index = imdb.get_word_index()34# 第一个指数是保留的5word_index = {k:(v+3) for k,v in word_index.items()}6word_index["<PAD>"] = 07word_index["<START>"] = 18word_index["<UNK>"] = 2 # unknown9word_index["<UNUSED>"] = 31011reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])1213def decode_review(text):14 return ' '.join([reverse_word_index.get(i, '?') for i in text])1516decode_review(train_data[0])xxxxxxxxxx41Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/imdb_word_index.json21646592/1641221 [==============================] - 0s 0us/step34"<START> this film was just brilliant casting location scenery story direction everyone's really suited the part they played and you could just imagine being there robert ..."
电影评论可以有不同的长度,我们将使用pad_sequences函数来标准化评论的长度:
xxxxxxxxxx131maxlen = 50023train_data = keras.preprocessing.sequence.pad_sequences(train_data,4 value=word_index["<PAD>"],5 padding='post',6 maxlen=maxlen)78test_data = keras.preprocessing.sequence.pad_sequences(test_data,9 value=word_index["<PAD>"],10 padding='post',11 maxlen=maxlen)12 13print(train_data[0]) 检查填充数据的第一个元素:
xxxxxxxxxx41[ 1 14 22 16 43 530 973 1622 1385 65 458 4468 66 394124 173 36 256 5 25 100 43 838 112 50 670 2 93...40 0 0 0 0 0 0 0 0 0]
3.2. 创建一个简单的模型
我们将使用 Keras Sequential API来定义我们的模型。
- 第一层是
Embedding层。该层采用整数编码的词汇表,并查找每个词索引的嵌入向量,这些向量是作为模型训练学习的,向量为输出数组添加维度,得到的维度是:(batch, sequence, embedding)。 - 接下来,
GlobalAveragePooling1D层通过对序列维度求平均,为每个示例返回固定长度的输出向量,这允许模型以尽可能最简单的方式处理可变长度的输入。 - 该固定长度输出矢量通过具有16个隐藏单元的完全连接(
Dense)层进行管道传输。 - 最后一层与单个输出节点密集连接,使用
sigmoid激活函数,此值是介于0和1之间的浮点值,表示评论为正的概率(或置信度)。
xxxxxxxxxx101embedding_dim=1623model = keras.Sequential([4 layers.Embedding(vocab_size, embedding_dim, input_length=maxlen),5 layers.GlobalAveragePooling1D(),6 layers.Dense(16, activation='relu'),7 layers.Dense(1, activation='sigmoid')8])910model.summary()xxxxxxxxxx161Model: "sequential"2_________________________________________________________________3Layer (type) Output Shape Param #4=================================================================5embedding_1 (Embedding) (None, 500, 16) 1600006_________________________________________________________________7global_average_pooling1d (Gl (None, 16) 08_________________________________________________________________9dense (Dense) (None, 16) 27210_________________________________________________________________11dense_1 (Dense) (None, 1) 1712=================================================================13Total params: 160,28914Trainable params: 160,28915Non-trainable params: 016_________________________________________________________________
3.3. 编译和训练模型
xxxxxxxxxx101model.compile(optimizer='adam',2 loss='binary_crossentropy',3 metrics=['accuracy'])45history = model.fit(6 train_data,7 train_labels,8 epochs=30,9 batch_size=512,10 validation_split=0.2)xxxxxxxxxx41Train on 20000 samples, validate on 5000 samples2...3Epoch 30/30420000/20000 [==============================] - 1s 54us/sample - loss: 0.1639 - accuracy: 0.9449 - val_loss: 0.2840 - val_accuracy: 0.8912
通过这种方法,我们的模型达到了大约88%的验证精度(注意模型过度拟合,训练精度显著提高)。
xxxxxxxxxx171import matplotlib.pyplot as plt23acc = history.history['accuracy']4val_acc = history.history['val_accuracy']56epochs = range(1, len(acc) + 1)78plt.figure(figsize=(12,9))9plt.plot(epochs, acc, 'bo', label='Training acc')10plt.plot(epochs, val_acc, 'b', label='Validation acc')11plt.title('Training and validation accuracy')12plt.xlabel('Epochs')13plt.ylabel('Accuracy')14plt.legend(loc='lower right')15plt.ylim((0.5,1))1617plt.show()xxxxxxxxxx21<Figure size 1200x900 with 1 Axes>2<Figure size 1200x900 with 1 Axes>
4. 检索学习的嵌入
接下来,让我们检索在训练期间学习的嵌入词,这将是一个形状矩阵 (vocab_size,embedding-dimension)。
xxxxxxxxxx31e = model.layers[0]2weights = e.get_weights()[0]3print(weights.shape) # shape: (vocab_size, embedding_dim)xxxxxxxxxx11(10000, 16)
我们现在将权重写入磁盘。要使用Embedding Projector,我们将以制表符分隔格式上传两个文件:向量文件(包含嵌入)和元数据文件(包含单词)。
xxxxxxxxxx111import io23out_v = io.open('vecs.tsv', 'w', encoding='utf-8')4out_m = io.open('meta.tsv', 'w', encoding='utf-8')5for word_num in range(vocab_size):6 word = reverse_word_index[word_num]7 embeddings = weights[word_num]8 out_m.write(word + "\n")9 out_v.write('\t'.join([str(x) for x in embeddings]) + "\n")10out_v.close()11out_m.close()如果您在Colaboratory中运行本教程,则可以使用以下代码段将这些文件下载到本地计算机(或使用文件浏览器, View -> Table of contents -> File browser)。
xxxxxxxxxx71try:2 from google.colab import files3except ImportError:4 pass5else:6 files.download('vecs.tsv')7 files.download('meta.tsv')5. 可视化嵌入
为了可视化我们的嵌入,我们将把它们上传到Embedding Projector。
- 点击“Load data”
- 上传我们上面创建的两个文件:
vecs.tsv和meta.tsv。
现在将显示您已训练的嵌入,您可以搜索单词以查找最近的邻居。例如,尝试搜索“beautiful”,你可能会看到像“wonderful”这样的邻居。注意:您的结果可能有点不同,这取决于在训练嵌入层之前如何随机初始化权重。
注意:通过实验,你可以使用更简单的模型生成更多可解释的嵌入,尝试删除Dense(16)层,重新训练模型,再次可视化嵌入。
6. 下一步
本教程向你展示了如何在小型数据集上从头开始训练和可视化词嵌入。
- 要了解有关嵌入Keras的更多信息,我们推荐FrançoisChollet推出的教程,链接。
- http://ivr-ahnu.cn/lectures/tf2/了解有关文本分类的更多信息(包括整体工作流程,如果您对何时使用嵌入与one-hot编码感到好奇),我们推荐Google的实战课程-文本分类指南。
最新版本:https://www.mashangxue123.com/tensorflow/tf2-tutorials-text-word_embeddings.html 英文版本:https://tensorflow.google.cn/beta/tutorials/text/word_embeddings 翻译建议PR:https://github.com/mashangxue/tensorflow2-zh/edit/master/r2/tutorials/text/word_embeddings.md