使用注意力机制给图片取标题 (tensorflow2.0官方教程翻译)
给定如下图像,我们的目标是生成一个标题,例如“冲浪者骑在波浪上”。

在这里,我们将使用基于注意力的模型。这使我们能够在生成标题时查看模型关注的图像部分。
模型体系结构类似于论文Show, Attend and Tell: Neural Image Caption Generation with Visual Attention.
本教程是一个端到端的例子。当您运行时,它下载 MS-COCO 数据集,使用Inception V3对图像子集进行预处理和缓存,训练一个编解码器模型,并使用训练过的模型对新图像生成标题。
在本例中,您将使用相对较少的数据来训练模型,大约20,000张图像对应30,000个标题(因为数据集中每个图像都有多个标题)。
导入库
x1from __future__ import absolute_import, division, print_function, unicode_literals23import tensorflow as tf45# We'll generate plots of attention in order to see which parts of an image6# our model focuses on during captioning7import matplotlib.pyplot as plt89# Scikit-learn includes many helpful utilities10from sklearn.model_selection import train_test_split11from sklearn.utils import shuffle1213import re14import numpy as np15import os16import time17import json18from glob import glob19from PIL import Image20import pickle1. 下载并准备MS-COCO数据集
您将使用MS-COCO数据集来训练我们的模型。该数据集包含超过82,000个图像,每个图像至少有5个不同的标题注释。下面的代码自动下载并提取数据集。 注意:训练集是一个13GB的文件。
xxxxxxxxxx151annotation_zip = tf.keras.utils.get_file('captions.zip',2 cache_subdir=os.path.abspath('.'),3 origin = 'http://images.cocodataset.org/annotations/annotations_trainval2014.zip',4 extract = True)5annotation_file = os.path.dirname(annotation_zip)+'/annotations/captions_train2014.json'67name_of_zip = 'train2014.zip'8if not os.path.exists(os.path.abspath('.') + '/' + name_of_zip):9 image_zip = tf.keras.utils.get_file(name_of_zip,10 cache_subdir=os.path.abspath('.'),11 origin = 'http://images.cocodataset.org/zips/train2014.zip',12 extract = True)13 PATH = os.path.dirname(image_zip)+'/train2014/'14else:15 PATH = os.path.abspath('.')+'/train2014/'2. (可选)限制训练集的大小以加快训练速度
对于本例,我们将选择30,000个标题的子集,并使用这些标题和相应的图像来训练我们的模型。与往常一样,如果您选择使用更多的数据,标题质量将会提高。
xxxxxxxxxx261# read the json file2with open(annotation_file, 'r') as f:3 annotations = json.load(f)45# storing the captions and the image name in vectors6all_captions = []7all_img_name_vector = []89for annot in annotations['annotations']:10 caption = '<start> ' + annot['caption'] + ' <end>'11 image_id = annot['image_id']12 full_coco_image_path = PATH + 'COCO_train2014_' + '%012d.jpg' % (image_id)1314 all_img_name_vector.append(full_coco_image_path)15 all_captions.append(caption)1617# shuffling the captions and image_names together18# setting a random state19train_captions, img_name_vector = shuffle(all_captions,20 all_img_name_vector,21 random_state=1)2223# selecting the first 30000 captions from the shuffled set24num_examples = 3000025train_captions = train_captions[:num_examples]26img_name_vector = img_name_vector[:num_examples]xxxxxxxxxx11len(train_captions), len(all_captions)xxxxxxxxxx11(30000, 414113)
3. 使用InceptionV3预处理图像
接下来,我们将使用InceptionV3(在Imagenet上预训练)对每个图像进行分类。我们将从最后一个卷积层中提取特征。
首先,我们需要将图像转换成inceptionV3期望的格式:
- 将图像大小调整为299px×299px
- 使用preprocess_input方法对图像进行预处理,使图像规范化,使其包含-1到1范围内的像素,这与用于训练InceptionV3的图像的格式相匹配。
xxxxxxxxxx61def load_image(image_path):2 img = tf.io.read_file(image_path)3 img = tf.image.decode_jpeg(img, channels=3)4 img = tf.image.resize(img, (299, 299))5 img = tf.keras.applications.inception_v3.preprocess_input(img)6 return img, image_path4. 初始化InceptionV3并加载预训练的Imagenet权重
现在您将创建一个 tf.keras 模型,其中输出层是 InceptionV3 体系结构中的最后一个卷积层。该层的输出形状为 8x8x2048 。使用最后一个卷积层是因为在这个例子中使用了注意力。您不会在训练期间执行此初始化,因为它可能会成为瓶颈。
- 您通过网络转发每个图像并将结果向量存储在字典中(image_name --> feature_vector)
- 在所有图像通过网络传递之后,您挑选字典并将其保存到磁盘。
xxxxxxxxxx61image_model = tf.keras.applications.InceptionV3(include_top=False,2 weights='imagenet')3new_input = image_model.input4hidden_layer = image_model.layers[-1].output56image_features_extract_model = tf.keras.Model(new_input, hidden_layer)5. 缓存从InceptionV3中提取的特性
您将使用InceptionV3预处理每个映像并将输出缓存到磁盘。缓存RAM中的输出会更快但内存密集,每个映像需要 8 * 8 * 2048 个浮点数。在撰写本文时,这超出了Colab的内存限制(目前为12GB内存)。
可以通过更复杂的缓存策略(例如,通过分割图像以减少随机访问磁盘 I/O)来提高性能,但这需要更多代码。
使用GPU在Clab中运行大约需要10分钟。如果您想查看进度条,可以: 使用GPU在Colab中运行大约需要10分钟。如果你想看到一个进度条,你可以:
- 安装tqdm (
!pip install tqdm), - 导入它(
from tqdm import tqdm), - 然后改变这一行:
for img, path in image_dataset:
to:
for img, path in tqdm(image_dataset):.
xxxxxxxxxx161# getting the unique images2encode_train = sorted(set(img_name_vector))34# feel free to change the batch_size according to your system configuration5image_dataset = tf.data.Dataset.from_tensor_slices(encode_train)6image_dataset = image_dataset.map(7 load_image, num_parallel_calls=tf.data.experimental.AUTOTUNE).batch(16)89for img, path in image_dataset:10 batch_features = image_features_extract_model(img)11 batch_features = tf.reshape(batch_features,12 (batch_features.shape[0], -1, batch_features.shape[3]))1314 for bf, p in zip(batch_features, path):15 path_of_feature = p.numpy().decode("utf-8")16 np.save(path_of_feature, bf.numpy())6. 对标题进行预处理和标记
- 首先,您将对标题进行标记(例如,通过拆分空格)。这为我们提供了数据中所有独特单词的词汇表(例如,“冲浪”,“足球”等)。
- 接下来,您将词汇量限制为前5,000个单词(以节省内存)。您将使用令牌“UNK”(未知)替换所有其他单词。
- 然后,您可以创建单词到索引和索引到单词的映射。
- 最后,将所有序列填充到与最长序列相同的长度。
xxxxxxxxxx31# This will find the maximum length of any caption in our dataset2def calc_max_length(tensor):3 return max(len(t) for t in tensor)xxxxxxxxxx91# The steps above is a general process of dealing with text processing23# choosing the top 5000 words from the vocabulary4top_k = 50005tokenizer = tf.keras.preprocessing.text.Tokenizer(num_words=top_k,6 oov_token="<unk>",7 filters='!"#$%&()*+.,-/:;=?@[\]^_`{|}~ ')8tokenizer.fit_on_texts(train_captions)9train_seqs = tokenizer.texts_to_sequences(train_captions)xxxxxxxxxx21tokenizer.word_index['<pad>'] = 02tokenizer.index_word[0] = '<pad>'xxxxxxxxxx21# creating the tokenized vectors2train_seqs = tokenizer.texts_to_sequences(train_captions)xxxxxxxxxx31# padding each vector to the max_length of the captions2# if the max_length parameter is not provided, pad_sequences calculates that automatically3cap_vector = tf.keras.preprocessing.sequence.pad_sequences(train_seqs, padding='post')xxxxxxxxxx31# calculating the max_length2# used to store the attention weights3max_length = calc_max_length(train_seqs)7. 将数据分解为训练和测试
xxxxxxxxxx51# Create training and validation sets using 80-20 split2img_name_train, img_name_val, cap_train, cap_val = train_test_split(img_name_vector,3 cap_vector,4 test_size=0.2,5 random_state=0)xxxxxxxxxx11len(img_name_train), len(cap_train), len(img_name_val), len(cap_val)xxxxxxxxxx11(24000, 24000, 6000, 6000)
8. 创建用于训练的tf.data数据集
我们的图片和标题已准备就绪!接下来,让我们创建一个tf.data数据集来用于训练我们的模型。
xxxxxxxxxx121# feel free to change these parameters according to your system's configuration23BATCH_SIZE = 644BUFFER_SIZE = 10005embedding_dim = 2566units = 5127vocab_size = len(tokenizer.word_index) + 18num_steps = len(img_name_train) // BATCH_SIZE9# shape of the vector extracted from InceptionV3 is (64, 2048)10# these two variables represent that11features_shape = 204812attention_features_shape = 64xxxxxxxxxx41# loading the numpy files2def map_func(img_name, cap):3 img_tensor = np.load(img_name.decode('utf-8')+'.npy')4 return img_tensor, capxxxxxxxxxx101dataset = tf.data.Dataset.from_tensor_slices((img_name_train, cap_train))23# using map to load the numpy files in parallel4dataset = dataset.map(lambda item1, item2: tf.numpy_function(5 map_func, [item1, item2], [tf.float32, tf.int32]),6 num_parallel_calls=tf.data.experimental.AUTOTUNE)78# shuffling and batching9dataset = dataset.shuffle(BUFFER_SIZE).batch(BATCH_SIZE)10dataset = dataset.prefetch(buffer_size=tf.data.experimental.AUTOTUNE)9. 模型
有趣的事实:下面的解码器与 注意神经机器翻译的示例中的解码器相同。
模型架构的灵感来自论文 Show, Attend and Tell 。
- 在这个例子中,你从InceptionV3的下卷积层中提取特征,给我们一个形状矢量(8, 8, 2048).
- 你将它压成(64,2048)的形状。
- 然后,该向量通过CNN编码器(由单个完全连接的层组成)。
- RNN(此处为GRU)参与图像以预测下一个单词。
xxxxxxxxxx261class BahdanauAttention(tf.keras.Model):2 def __init__(self, units):3 super(BahdanauAttention, self).__init__()4 self.W1 = tf.keras.layers.Dense(units)5 self.W2 = tf.keras.layers.Dense(units)6 self.V = tf.keras.layers.Dense(1)78 def call(self, features, hidden):9 # features(CNN_encoder output) shape == (batch_size, 64, embedding_dim)1011 # hidden shape == (batch_size, hidden_size)12 # hidden_with_time_axis shape == (batch_size, 1, hidden_size)13 hidden_with_time_axis = tf.expand_dims(hidden, 1)1415 # score shape == (batch_size, 64, hidden_size)16 score = tf.nn.tanh(self.W1(features) + self.W2(hidden_with_time_axis))1718 # attention_weights shape == (batch_size, 64, 1)19 # we get 1 at the last axis because we are applying score to self.V20 attention_weights = tf.nn.softmax(self.V(score), axis=1)2122 # context_vector shape after sum == (batch_size, hidden_size)23 context_vector = attention_weights * features24 context_vector = tf.reduce_sum(context_vector, axis=1)2526 return context_vector, attention_weightsxxxxxxxxxx121class CNN_Encoder(tf.keras.Model):2 # Since we have already extracted the features and dumped it using pickle3 # This encoder passes those features through a Fully connected layer4 def __init__(self, embedding_dim):5 super(CNN_Encoder, self).__init__()6 # shape after fc == (batch_size, 64, embedding_dim)7 self.fc = tf.keras.layers.Dense(embedding_dim)89 def call(self, x):10 x = self.fc(x)11 x = tf.nn.relu(x)12 return xxxxxxxxxxx411class RNN_Decoder(tf.keras.Model):2 def __init__(self, embedding_dim, units, vocab_size):3 super(RNN_Decoder, self).__init__()4 self.units = units56 self.embedding = tf.keras.layers.Embedding(vocab_size, embedding_dim)7 self.gru = tf.keras.layers.GRU(self.units,8 return_sequences=True,9 return_state=True,10 recurrent_initializer='glorot_uniform')11 self.fc1 = tf.keras.layers.Dense(self.units)12 self.fc2 = tf.keras.layers.Dense(vocab_size)1314 self.attention = BahdanauAttention(self.units)1516 def call(self, x, features, hidden):17 # defining attention as a separate model18 context_vector, attention_weights = self.attention(features, hidden)1920 # x shape after passing through embedding == (batch_size, 1, embedding_dim)21 x = self.embedding(x)2223 # x shape after concatenation == (batch_size, 1, embedding_dim + hidden_size)24 x = tf.concat([tf.expand_dims(context_vector, 1), x], axis=-1)2526 # passing the concatenated vector to the GRU27 output, state = self.gru(x)2829 # shape == (batch_size, max_length, hidden_size)30 x = self.fc1(output)3132 # x shape == (batch_size * max_length, hidden_size)33 x = tf.reshape(x, (-1, x.shape[2]))3435 # output shape == (batch_size * max_length, vocab)36 x = self.fc2(x)3738 return x, state, attention_weights3940 def reset_state(self, batch_size):41 return tf.zeros((batch_size, self.units))xxxxxxxxxx21encoder = CNN_Encoder(embedding_dim)2decoder = RNN_Decoder(embedding_dim, units, vocab_size)xxxxxxxxxx121optimizer = tf.keras.optimizers.Adam()2loss_object = tf.keras.losses.SparseCategoricalCrossentropy(3 from_logits=True, reduction='none')45def loss_function(real, pred):6 mask = tf.math.logical_not(tf.math.equal(real, 0))7 loss_ = loss_object(real, pred)89 mask = tf.cast(mask, dtype=loss_.dtype)10 loss_ *= mask1112 return tf.reduce_mean(loss_)10. Checkpoint 检查点
xxxxxxxxxx51checkpoint_path = "./checkpoints/train"2ckpt = tf.train.Checkpoint(encoder=encoder,3 decoder=decoder,4 optimizer = optimizer)5ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)xxxxxxxxxx31start_epoch = 02if ckpt_manager.latest_checkpoint:3 start_epoch = int(ckpt_manager.latest_checkpoint.split('-')[-1])11. 训练
- 您提取各自.npy文件中存储的特性,然后通过编码器传递这些特性。
- 编码器输出,隐藏状态(初始化为0)和解码器输入(它是开始标记)被传递给解码器。
- 解码器返回预测和解码器隐藏状态。
- 然后将解码器隐藏状态传递回模型,并使用预测来计算损失。
- 使用teacher forcing决定解码器的下一个输入。
- Teacher forcing 是将目标字作为下一个输入传递给解码器的技术。
- 最后一步是计算梯度,并将其应用于优化器和反向传播。
xxxxxxxxxx31# adding this in a separate cell because if you run the training cell2# many times, the loss_plot array will be reset3loss_plot = []xxxxxxxxxx311.function2def train_step(img_tensor, target):3 loss = 045 # initializing the hidden state for each batch6 # because the captions are not related from image to image7 hidden = decoder.reset_state(batch_size=target.shape[0])89 dec_input = tf.expand_dims([tokenizer.word_index['<start>']] * BATCH_SIZE, 1)1011 with tf.GradientTape() as tape:12 features = encoder(img_tensor)1314 for i in range(1, target.shape[1]):15 # passing the features through the decoder16 predictions, hidden, _ = decoder(dec_input, features, hidden)1718 loss += loss_function(target[:, i], predictions)1920 # using teacher forcing21 dec_input = tf.expand_dims(target[:, i], 1)2223 total_loss = (loss / int(target.shape[1]))2425 trainable_variables = encoder.trainable_variables + decoder.trainable_variables2627 gradients = tape.gradient(loss, trainable_variables)2829 optimizer.apply_gradients(zip(gradients, trainable_variables))3031 return loss, total_lossxxxxxxxxxx221EPOCHS = 2023for epoch in range(start_epoch, EPOCHS):4 start = time.time()5 total_loss = 067 for (batch, (img_tensor, target)) in enumerate(dataset):8 batch_loss, t_loss = train_step(img_tensor, target)9 total_loss += t_loss1011 if batch % 100 == 0:12 print ('Epoch {} Batch {} Loss {:.4f}'.format(13 epoch + 1, batch, batch_loss.numpy() / int(target.shape[1])))14 # storing the epoch end loss value to plot later15 loss_plot.append(total_loss / num_steps)1617 if epoch % 5 == 0:18 ckpt_manager.save()1920 print ('Epoch {} Loss {:.6f}'.format(epoch + 1,21 total_loss/num_steps))22 print ('Time taken for 1 epoch {} sec\n'.format(time.time() - start))xxxxxxxxxx81......2Epoch 20 Batch 0 Loss 0.35683Epoch 20 Batch 100 Loss 0.32884Epoch 20 Batch 200 Loss 0.33575Epoch 20 Batch 300 Loss 0.29456Epoch 20 Loss 0.3586187Time taken for 1 epoch 186.8766734600067 sec8
xxxxxxxxxx51plt.plot(loss_plot)2plt.xlabel('Epochs')3plt.ylabel('Loss')4plt.title('Loss Plot')5plt.show()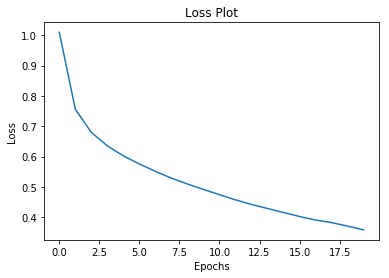
12. 标题!
- 评估函数类似于训练循环,只是这里不使用 teacher forcing 。解码器在每个时间步长的输入是其先前的预测,以及隐藏状态和编码器的输出。
- 当模型预测结束令牌时停止预测。
- 并存储每个时间步的注意力。
xxxxxxxxxx291def evaluate(image):2 attention_plot = np.zeros((max_length, attention_features_shape))34 hidden = decoder.reset_state(batch_size=1)56 temp_input = tf.expand_dims(load_image(image)[0], 0)7 img_tensor_val = image_features_extract_model(temp_input)8 img_tensor_val = tf.reshape(img_tensor_val, (img_tensor_val.shape[0], -1, img_tensor_val.shape[3]))910 features = encoder(img_tensor_val)1112 dec_input = tf.expand_dims([tokenizer.word_index['<start>']], 0)13 result = []1415 for i in range(max_length):16 predictions, hidden, attention_weights = decoder(dec_input, features, hidden)1718 attention_plot[i] = tf.reshape(attention_weights, (-1, )).numpy()1920 predicted_id = tf.argmax(predictions[0]).numpy()21 result.append(tokenizer.index_word[predicted_id])2223 if tokenizer.index_word[predicted_id] == '<end>':24 return result, attention_plot2526 dec_input = tf.expand_dims([predicted_id], 0)2728 attention_plot = attention_plot[:len(result), :]29 return result, attention_plotxxxxxxxxxx151def plot_attention(image, result, attention_plot):2 temp_image = np.array(Image.open(image))34 fig = plt.figure(figsize=(10, 10))56 len_result = len(result)7 for l in range(len_result):8 temp_att = np.resize(attention_plot[l], (8, 8))9 ax = fig.add_subplot(len_result//2, len_result//2, l+1)10 ax.set_title(result[l])11 img = ax.imshow(temp_image)12 ax.imshow(temp_att, cmap='gray', alpha=0.6, extent=img.get_extent())1314 plt.tight_layout()15 plt.show()xxxxxxxxxx111# captions on the validation set2rid = np.random.randint(0, len(img_name_val))3image = img_name_val[rid]4real_caption = ' '.join([tokenizer.index_word[i] for i in cap_val[rid] if i not in [0]])5result, attention_plot = evaluate(image)67print ('Real Caption:', real_caption)8print ('Prediction Caption:', ' '.join(result))9plot_attention(image, result, attention_plot)10# opening the image11Image.open(img_name_val[rid])xxxxxxxxxx41Real Caption: <start> a man gets ready to hit a ball with a bat <end>2Prediction Caption: a baseball player begins to bat <end>3真实的标题:一个人准备用球棒击球4预测标题: 棒球运动员开始击球


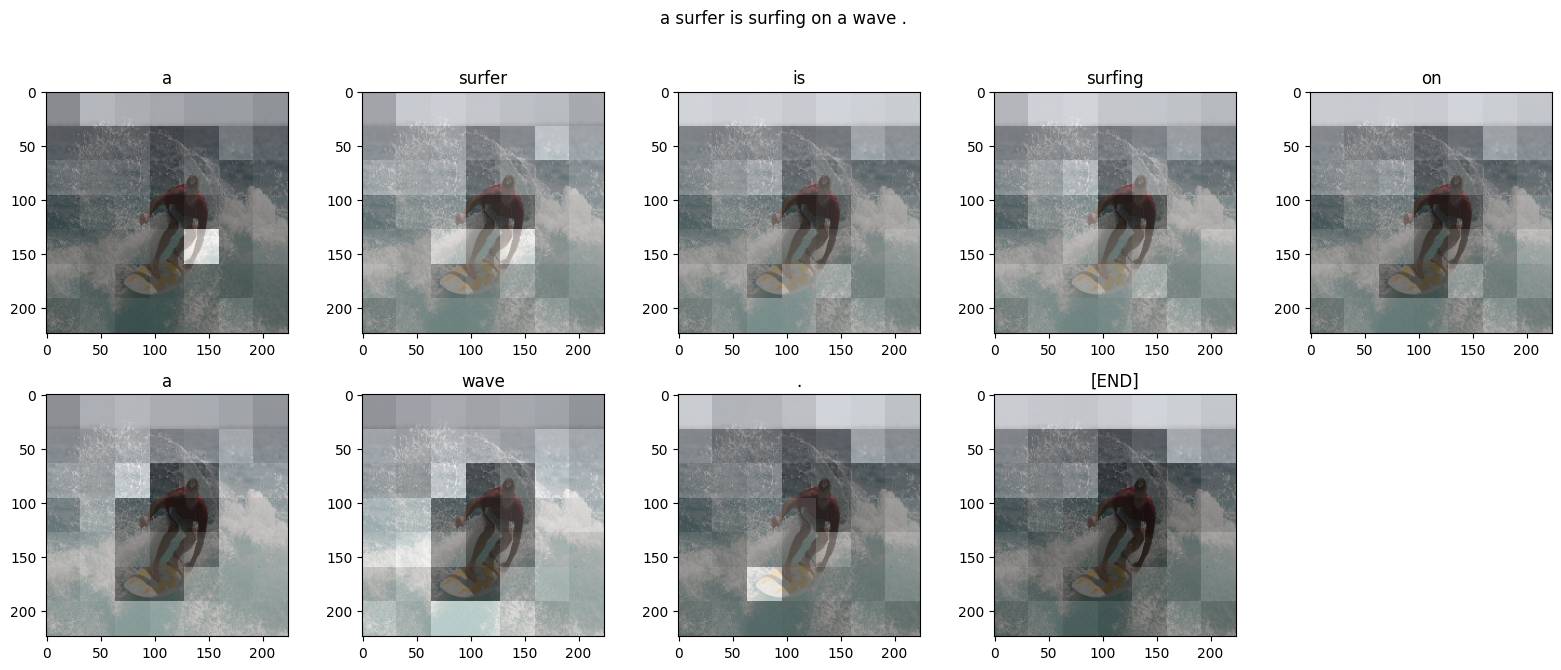
13. 在你自己的图片上试试
为了好玩,下面我们提供了一种方法,您可以使用我们刚刚训练过的模型为您自己的图像添加标题。请记住,它是在相对少量的数据上训练的,您的图像可能与训练数据不同(因此请为奇怪的结果做好准备!)
xxxxxxxxxx101image_url = 'https://tensorflow.org/images/surf.jpg'2image_extension = image_url[-4:]3image_path = tf.keras.utils.get_file('image'+image_extension,4 origin=image_url)56result, attention_plot = evaluate(image_path)7print ('Prediction Caption:', ' '.join(result))8plot_attention(image_path, result, attention_plot)9# opening the image10Image.open(image_path)xxxxxxxxxx21Prediction Caption: a man riding a surf board in the water <end>2预测标题:一名男子在水中骑冲浪板


下一步
恭喜!您刚刚训练了一个注意力机制给图像取标题的模型。接下来,看一下这个使用注意力机制的神经机器翻译示例。它使用类似的架构来翻译西班牙语和英语句子。您还可以尝试在不同的数据集上训练此笔记本中的代码。
最新版本:https://www.mashangxue123.com/tensorflow/tf2-tutorials-text-image_captioning.html 英文版本:https://tensorflow.google.cn/beta/tutorials/text/image_captioning 翻译建议PR:https://github.com/mashangxue/tensorflow2-zh/edit/master/r2/tutorials/text/image_captioning.md